The Precision of Estimates of Nonresponse Bias in Means
Abstract
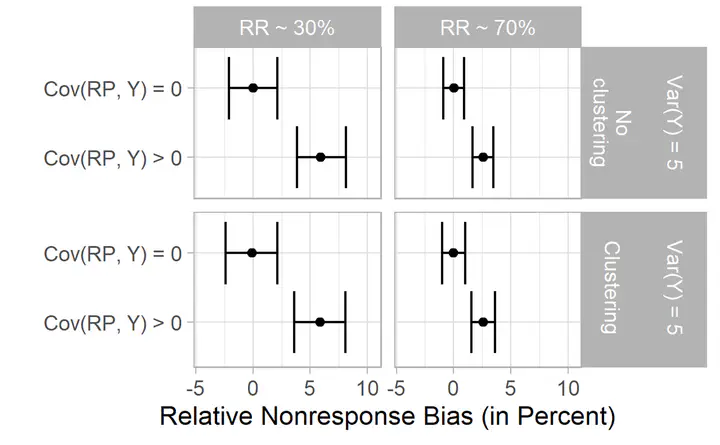
Survey data producers increasingly provide estimates of nonresponse bias in several variables when they release or analyze data. Researchers understand that sample estimates of population values should be reported with appropriate measures of uncertainty, such as standard errors or confidence intervals. However, few studies acknowledge that nonresponse bias estimates vary across samples. Using simulations, we study the precision of estimates of nonresponse bias in means and how that precision is affected by features such as clustering and response rates. Results show that low response rates and clustering increase the variability of bias estimates. We then evaluate three methods to estimate the sampling variance of nonresponse bias in means: a method developed by Lee (2006), jackknife replication, and linearization. We find that the Lee approach works well for simple random samples but overestimates variability for clustered samples. Linearization and replication work well with all populations studied, and we give an algorithm for the implementation of these approaches. We also apply the three methods to the LISS panel and the General Social Survey, providing practical confirmation of the simulation results.